Data Anonymization یا ناشناس سازی دادهها فرآیندی در راستای حفاظت از اطلاعات خصوصی و حساس کاربران است. این اقدام از طریق پاک کردن یا رمزنگاری بخشهایی از اطلاعات است که اشخاص را به صورت مستقیم به دادهها مربوط میسازد. برای مثال در طی این فرآیند شاخصهایی مانند نامها، آدرسها و رمزهای عبور از بین دادهها حذف میشوند و در عین باقی ماندن اصل اطلاعات این موارد ناشناس باقی خواهند ماند.
روشهای Data Anonymization
Data masking : شامل پنهان کردن از طریق تغییر مقادیر. این امکان وجود دارد که نسخه میروری از دیتابیس تهیه و تغییرات لازم را بر روی آن اعمال نمایید. تغییرات میتوانند از طریق روشهایی همچون به هم ریختن کاراکترها یا رمزنگاری صورت بگیرند. این روش امکان تشخیص یا مهندسی معکوس را به صفر نزدیک میکند.
Pseudonymization: یک روش مدیریت اطلاعات است که طی آن اطلاعات شخصی کاربران با شاخصهای یا اسامی مستعار جایگزین میشوند. برای مثال نام محمد محمدی با عبارت Client 3925 و یا عبارت با مفهوم تری همچون علی عباسی جایگزین میشود. این روش باعث حفظ یکپارچگی و صحت دادهها میشود و در عین حفاظت از اطلاعات این اجازه را میدهد تا اطلاعات برای مقاصد مورد نیاز بعدی به صورت کامل استفاده شوند.
Generalization: در این روش حذف تعمدی بخشی از اطلاعات به جهت حفاظت از آنها انجام میشود. در این مدل با توجه به میزان نیاز، دادهها تا حدود مشخصی حذف میگردند. برای مثال در یک آدرس امکان حذف شماره پلاک بدون حذف باقی آدرس وجود خواهد داشت.
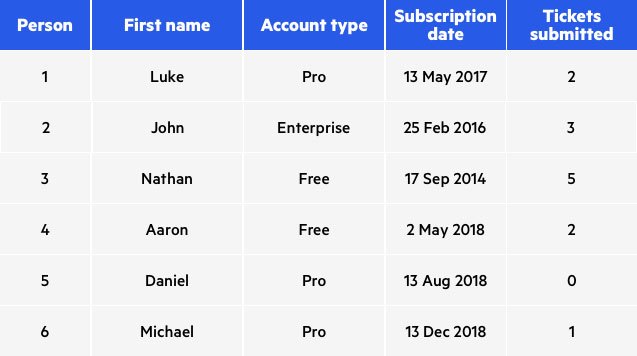
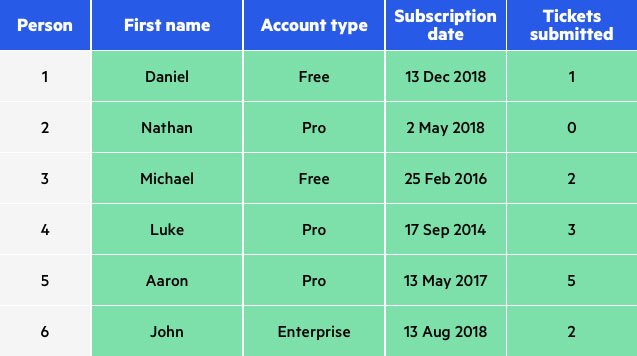
Data swapping: تکنیکی است که طی آن کاراکترها، سطرها و یا ستون دادههای موجود در دیتابیس جابهجا یا به نوعی به صورت مجدد ساختاربندی میشوند تا به این ترتیب اشاره مستقیمی به اصل اطلاعات نداشته باشند. این روش به نامهای بر زدن یا جایگشت دهی اطلاعات نیز شناخته میشود(Shuffling – Permutation). برای مثال ممکن است تاریخهای تولد موجود در یک سطر با یکدیگر یا مقادیر ستونهای دیگر جا به جا شوند.
Data perturbation: دادههای اصلی به صورت مختصر بوسیله تکنیکهایی همچون گرد کردن اعداد یا اضافه کردن نویز تغییر مییابند. در این مدل میزان نویز یا گرد کردن اهمیت بالایی دارد چرا که در صورت کم بودن این مقدار Anonymization به شکل ضعیفی پیادهسازی میشود و در صورت بالا بودن آن نیز دادهها فاصله زیادی با واقعیت پیدا کرده و عملا غیر قابل استفاده میشوند. برای مثال در امر سن افراد امکان گرد کردن تنها تا یک عدد به صورت کلی امکان پذیر است در صورتیکه در خصوص شماره پلاکها گرد کردن یک عددی فایده چندانی ندارد. در مقابل نویزدهی به شکلی که اعداد در مقداری همچون 12 ضرب شوند همچنان واقعی بودن داده را حفظ میکند، در حالیکه منجر به غیر واقعی شدن آشکار سنین افراد میگردد.
Synthetic data: خلق اطلاعاتی توسط الگوریتمهای مشخص که هیچگونه ارتباطی با اصل دادهها ندارند. این روش برای ایجاد یک دسته اطلاعات جعلی، به جای تغییر اصل اطلاعات استفاده میشود. این فرآیند شامل خلق مدلهای آماری مشابه با دیتا اصلی بر اساس الگو یافت شده موجود در دادههای اولیه است. در این راه میتوان از تکنیکهایی همچون استفاده از انحراف معیار، میانه یا رگرسیون خطی استفاده نمود.
در زیر نمونهای از Data swapping قابل مشاهده است، تصویر اول اطلاعات اصلی و تصویر دوم اطلاعات پس از جابهجایی دادهاست: